СТАТЬИ
Плотность ключевого слова нонсенс
Линеаризация
Линеаризация - это процесс игнорирования разметочных тегов веб-документа, в результате которого контент представляется для дальнейшего анализа в виде набора символов. Этот процесс анализирует тег за тегом, по мере обнаружения тегов в исходном коде. Как видно из рис. 1, линеаризация влияет на то, каким образом поисковые системы "видят", "читают" и "оценивают" веб-контент - если можно так выразиться. В данном примере, контент вебсайта подвергается рендерингу с использованием двух вложенных html-страниц, каждая из которых состоит из одной большой ячейки сверху, и обычного 3-колоночного формата ячеек ниже. Мы полагаем, что в исходном коде больше не содержится другого текста и html-тегов. Номера в правых верхних углах ячеек показывают, в каком порядке поисковая система обнаруживает и интерпретирует контент ячеек.
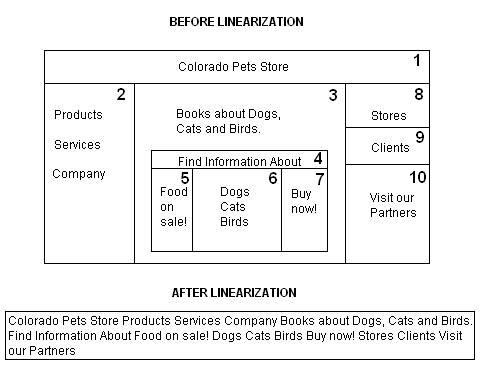
Рис. 1. Линеаризация веб-контента, представленного в табличном виде
Блок внизу рис. 1 иллюстрирует, каким образом поисковая система может "видеть", "читать" и "интерпретировать" контент этого документа после линеаризации. Обратите внимание на отсутствие «связности» и тематического деления. Две последовательности терминов иллюстрируют ситуацию: "Find Information About Food on sale!" и "Clients Visit our Partners". Такое представление контента скорее всего, скрыто от нетренированного глаза среднего пользователя. Очевидно, что линеаризация оказывает губительный эффект на позиционирование ключевого слова, на близость, распределение и на то, как "оценивается" и учитывается эффективный контент. Ситуация усугубляется, если используется несколько вложенных таблиц и html-тегов, до такой степени, что контент, воспринимаемый человеком как достойный внимания, может интерпретироваться поисковой системой как обыкновенный хлам. Так что, рассчитывать локальные значения KD - неблагодарное занятие.
Сжигание деревьев (Burning the Trees) и борьба за вес ключевого слова
При самом оптимальном сценарии, линеаризация показывает, могут ли слова, фразы и абзацы бороться за релевантность в искаженном лексикографическом дереве. Я называю это явление "сжиганием деревьев". Это одна из наиболее часто упускаемых из вида проблем веб-дизайна и оптимизации.
Конструируя лексикографическое дерево на основе линеаризованного контента, можно получить фактическое состояние и взаимоотношения между существительными, прилагательными, глаголами и фразами, исходя из того, как они фактически включены в документы. Оно показывает используемую структуру данных. Во многих случаях, линеаризация определяет локальные концепции документа (группы существительных) и скрытые грамматические шаблоны (patterns). Мандельброт (Mandelbrot) предложил использовать параметр, который он назвал "температурой разговора", исходя из шаблонной природы языка, наблюдаемой в лексикографических деревьях. Он пишет: " Чем 'горячее' разговор, тем выше вероятность использования редких слов." Однако, с семантической точки зрения, редкость слова имеет зависимость от контекста. Таким образом, я полагаю, что "сжигание деревьев" является естественным следствием неверно расположенных терминов.
В своей работе Fractals and Sentence Production, часть 9 From Complexity to Creativity, Бен Гертцель (Ben Goertzel) использует модель L-System, чтобы объяснить, каким образом в раннем детстве происходит формирование детской грамматики. Сначала получается предложение из двух слов, в котором разговорный лоскут включает в себя существительные (С) и глаголы (Г), а затем происходит замена Г на ГС (Г >> ГС). Пояснить эти две разговорные стадии можно следующим примером:
0 С Г (Stevie byebye)
1 С Г С (Stevie byebye car)
Линеаризация - это процесс игнорирования разметочных тегов веб-документа, в результате которого контент представляется для дальнейшего анализа в виде набора символов. Этот процесс анализирует тег за тегом, по мере обнаружения тегов в исходном коде. Как видно из рис. 1, линеаризация влияет на то, каким образом поисковые системы "видят", "читают" и "оценивают" веб-контент - если можно так выразиться. В данном примере, контент вебсайта подвергается рендерингу с использованием двух вложенных html-страниц, каждая из которых состоит из одной большой ячейки сверху, и обычного 3-колоночного формата ячеек ниже. Мы полагаем, что в исходном коде больше не содержится другого текста и html-тегов. Номера в правых верхних углах ячеек показывают, в каком порядке поисковая система обнаруживает и интерпретирует контент ячеек.
Рис. 1. Линеаризация веб-контента, представленного в табличном виде
Блок внизу рис. 1 иллюстрирует, каким образом поисковая система может "видеть", "читать" и "интерпретировать" контент этого документа после линеаризации. Обратите внимание на отсутствие «связности» и тематического деления. Две последовательности терминов иллюстрируют ситуацию: "Find Information About Food on sale!" и "Clients Visit our Partners". Такое представление контента скорее всего, скрыто от нетренированного глаза среднего пользователя. Очевидно, что линеаризация оказывает губительный эффект на позиционирование ключевого слова, на близость, распределение и на то, как "оценивается" и учитывается эффективный контент. Ситуация усугубляется, если используется несколько вложенных таблиц и html-тегов, до такой степени, что контент, воспринимаемый человеком как достойный внимания, может интерпретироваться поисковой системой как обыкновенный хлам. Так что, рассчитывать локальные значения KD - неблагодарное занятие.
Сжигание деревьев (Burning the Trees) и борьба за вес ключевого слова
При самом оптимальном сценарии, линеаризация показывает, могут ли слова, фразы и абзацы бороться за релевантность в искаженном лексикографическом дереве. Я называю это явление "сжиганием деревьев". Это одна из наиболее часто упускаемых из вида проблем веб-дизайна и оптимизации.
Конструируя лексикографическое дерево на основе линеаризованного контента, можно получить фактическое состояние и взаимоотношения между существительными, прилагательными, глаголами и фразами, исходя из того, как они фактически включены в документы. Оно показывает используемую структуру данных. Во многих случаях, линеаризация определяет локальные концепции документа (группы существительных) и скрытые грамматические шаблоны (patterns). Мандельброт (Mandelbrot) предложил использовать параметр, который он назвал "температурой разговора", исходя из шаблонной природы языка, наблюдаемой в лексикографических деревьях. Он пишет: " Чем 'горячее' разговор, тем выше вероятность использования редких слов." Однако, с семантической точки зрения, редкость слова имеет зависимость от контекста. Таким образом, я полагаю, что "сжигание деревьев" является естественным следствием неверно расположенных терминов.
В своей работе Fractals and Sentence Production, часть 9 From Complexity to Creativity, Бен Гертцель (Ben Goertzel) использует модель L-System, чтобы объяснить, каким образом в раннем детстве происходит формирование детской грамматики. Сначала получается предложение из двух слов, в котором разговорный лоскут включает в себя существительные (С) и глаголы (Г), а затем происходит замена Г на ГС (Г >> ГС). Пояснить эти две разговорные стадии можно следующим примером:
0 С Г (Stevie byebye)
1 С Г С (Stevie byebye car)
обсудить (14)