СТАТЬИ
Плотность ключевого слова нонсенс
24 марта общий поиск в Google по "keyword density optimization" возвратил 240 000 документов. Я обратил внимание, что большая часть этих документов принадлежит специалистам в области поискового маркетинга и оптимизации (SEM, SEO). Некоторые из них продвигают инструменты по анализу плотности ключевых слов (keyword density - KD), другие рассказывают о "правильном распределении плотности", "наилучшей плотности ключевых слов", о показателе KD, который отражает "концентрацию" или "мощность", и тому подобное. Некоторые даже рассматривают KD как вес термина i в документе j, а кое-кто идет дальше и предлагает отслеживать локальный уровень KD в заголовках, описаниях, параграфах, таблицах, ссылках, URL, и т.д. А кто-то не поленился найти специалистов, которые проделали очередной "фокус" с KD и теперь утверждают, что оптимизация значений KD до определенного уровня в отдельно взятой поисковой системе, влияет на степень релевантности и ранг документа в этой поисковой системе.
Учитывая тот факт, что развелось слишком много теорий относительно KD, мой хороший друг Майк Грехен (Mike Grehan) отыскал меня после конференции Jupitermedia 2005 по стратегиям в поисковых системах, которая проводилась в Нью-Йорке, и предложил мне как-то отреагировать по этому вопросу. Я подумал, что наше "решение" должно быть в виде разносторонней статьи, содержащей немного сведений из области получения информации, с примесью семантического анализа и математических элементов, однако без однозначных выводов, чтобы читатели могли принять собственное решение. Итак, поехали.
Основные понятия
В литературе по поисковому маркетингу, плотность ключевого слова определяется как Уравнение 1,
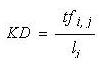
Уравнение 1.
где tfi, j означает сколько раз термин i появляется в документе j, а l - общее количество терминов в документе. Равенство 1 досталось по наследству от старой литературы по теории читабельности, когда показатели частоты слова рассчитывались для отдельных частей - фраз, предложений, параграфов, или для целого документа, в сочетании с другими тестами на читабельность.
Отслеживание значений плотности ключевых слов плотно вошло во все коммерческие поисковые системы и в Интернет в целом, хотя этот подход с трудом вписывается в теорию о получении информации (IR – information retrieval). Хуже того, KD не играет роли при обработке текста, индексировании документов или присвоении веса терминам коммерческими поисковыми системами. Почему же многие оптимизаторы продолжают верить в силу значений KD? Ответ прост: неверная информация.
Если два документа, D1 и D2, состоят из 1000 терминов (l = 1000) и нужный термин повторяется 20 раз (tf = 20) то для обоих документов KD = 20/1000 = 0,02 (или 2%) по этому термину. Такие же значения получаются при tf = 10 и l = 500.
Очевидно, что обобщенное значение не сообщает нам ничего:
1. Об относительном расстоянии между ключевыми словами в документах (proximity)
2. Где в документе встречаются ключевые слова (distribution)
3. О частоте совместного цитирования терминов (co-occurence)
4. Об основной теме, предмете и подтемах документов
Таким образом, KD уходит от оценки качества контента, семантики и релевантности. В таких условиях сложно обсуждать вопросы оптимизации удельного веса слов, в связи с ранкингом документа. Учитывая, что при этом нужно обращать внимание на стиль документа, вы должны понять, почему статья называется "Плотность ключевого слова нонсенс"
Для прояснения вопроса рассмотрим следующие пять приемов, используемых в работе поисковых систем.
1. Линеаризация (Linearization)
2. Токенизация (Tokenization)
3. Фильтрация (Filtration)
4. Стемминг (Stemming)
5. Взвешивание (Weighting)
Учитывая тот факт, что развелось слишком много теорий относительно KD, мой хороший друг Майк Грехен (Mike Grehan) отыскал меня после конференции Jupitermedia 2005 по стратегиям в поисковых системах, которая проводилась в Нью-Йорке, и предложил мне как-то отреагировать по этому вопросу. Я подумал, что наше "решение" должно быть в виде разносторонней статьи, содержащей немного сведений из области получения информации, с примесью семантического анализа и математических элементов, однако без однозначных выводов, чтобы читатели могли принять собственное решение. Итак, поехали.
Основные понятия
В литературе по поисковому маркетингу, плотность ключевого слова определяется как Уравнение 1,
Уравнение 1.
где tfi, j означает сколько раз термин i появляется в документе j, а l - общее количество терминов в документе. Равенство 1 досталось по наследству от старой литературы по теории читабельности, когда показатели частоты слова рассчитывались для отдельных частей - фраз, предложений, параграфов, или для целого документа, в сочетании с другими тестами на читабельность.
Отслеживание значений плотности ключевых слов плотно вошло во все коммерческие поисковые системы и в Интернет в целом, хотя этот подход с трудом вписывается в теорию о получении информации (IR – information retrieval). Хуже того, KD не играет роли при обработке текста, индексировании документов или присвоении веса терминам коммерческими поисковыми системами. Почему же многие оптимизаторы продолжают верить в силу значений KD? Ответ прост: неверная информация.
Если два документа, D1 и D2, состоят из 1000 терминов (l = 1000) и нужный термин повторяется 20 раз (tf = 20) то для обоих документов KD = 20/1000 = 0,02 (или 2%) по этому термину. Такие же значения получаются при tf = 10 и l = 500.
Очевидно, что обобщенное значение не сообщает нам ничего:
Таким образом, KD уходит от оценки качества контента, семантики и релевантности. В таких условиях сложно обсуждать вопросы оптимизации удельного веса слов, в связи с ранкингом документа. Учитывая, что при этом нужно обращать внимание на стиль документа, вы должны понять, почему статья называется "Плотность ключевого слова нонсенс"
Для прояснения вопроса рассмотрим следующие пять приемов, используемых в работе поисковых систем.
обсудить (14)